Google Colab에서 PDF 파일 처리 및 Excel 데이터로 페이지 추출하는 방법
이 글에서는 Google Colab을 사용해 Excel 파일의 데이터를 읽고, 각 행에 있는 PDF 파일에서 특정 페이지를 추출하는 방법을 소개합니다. 이 과정에서 PyPDF2와 pandas 라이브러리를 활용하게 되며, Google Drive에 저장된 파일을 다루는 방법도 포함됩니다.
만약 코랩을 다루는 것은 익숙하다면, 블로그 중반부 부터 본격적인 PDF 분할 이야기를 확인하면 됩니다.
1. Google Colab 소개
Google Colab은 클라우드 기반의 무료 Python 환경으로, 머신러닝, 데이터 분석, 그리고 다양한 Python 작업을 할 수 있습니다. 특히 Google Drive와의 연동이 쉬워, 로컬에서 할 수 있는 작업들을 클라우드에서 쉽게 처리할 수 있습니다.
특히 구글 계정만 있으면 누구나 사용할 수 있기 때문에 더욱 작업이 간편합니다.
https://colab.research.google.com/?authuser=0#create=true
Google Colab
colab.research.google.com
2. Google Colab 시작하기
위 링크를 클릭하면, 일반적으로 자신의 구글 계정을 통해 로그인 하게 되고 몇가지 단계를 거치면 '노트북'이라는 작업환경이 나옵니다.
아래 화면과 같이 나온다면 성공입니다.

3. Google Drive 마운트
Google Colab에서 Google Drive에 있는 파일에 접근하려면, 먼저 Google Drive를 마운트해야 합니다. 아래 코드를 첫 번째 셀에 입력하여 Drive를 마운트합니다.
from google.colab import drive
drive.mount('/content/drive')
실행 후, Google 계정에 로그인하고 권한을 부여하면 Google Drive가 Colab 환경에 연결됩니다.
4. 필요한 라이브러리 설치
Google Colab은 기본적인 Python 환경을 제공하지만, 특정 라이브러리는 설치해야 합니다. 이 프로젝트에서는 PyPDF2와 pandas가 필요합니다. 다음 명령어를 사용하여 라이브러리를 설치합니다.
!pip install PyPDF2 pandas
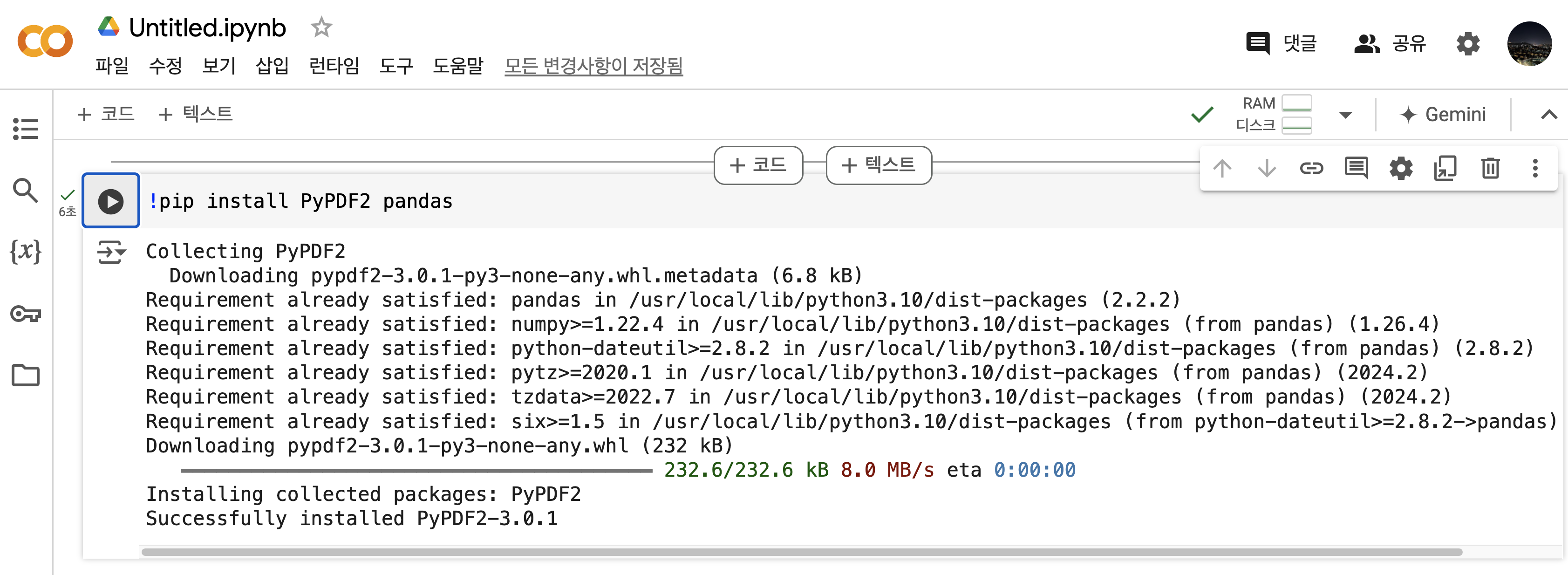
여기까지 실행을 완료했다면, 본격적으로 PDF 파일을 분할하는 과정을 진행할 수 있다.
5. 설정 변수 및 데이터 불러오기
이제 PDF 파일과 Excel 파일을 불러와서 처리할 준비를 합니다. 이때 PDF 파일들은 Google Drive에, 페이지 번호가 기록된 Excel 파일 역시 Google Drive에 저장되어 있어야 합니다. (경로 확인 필요, 이미지 참고)
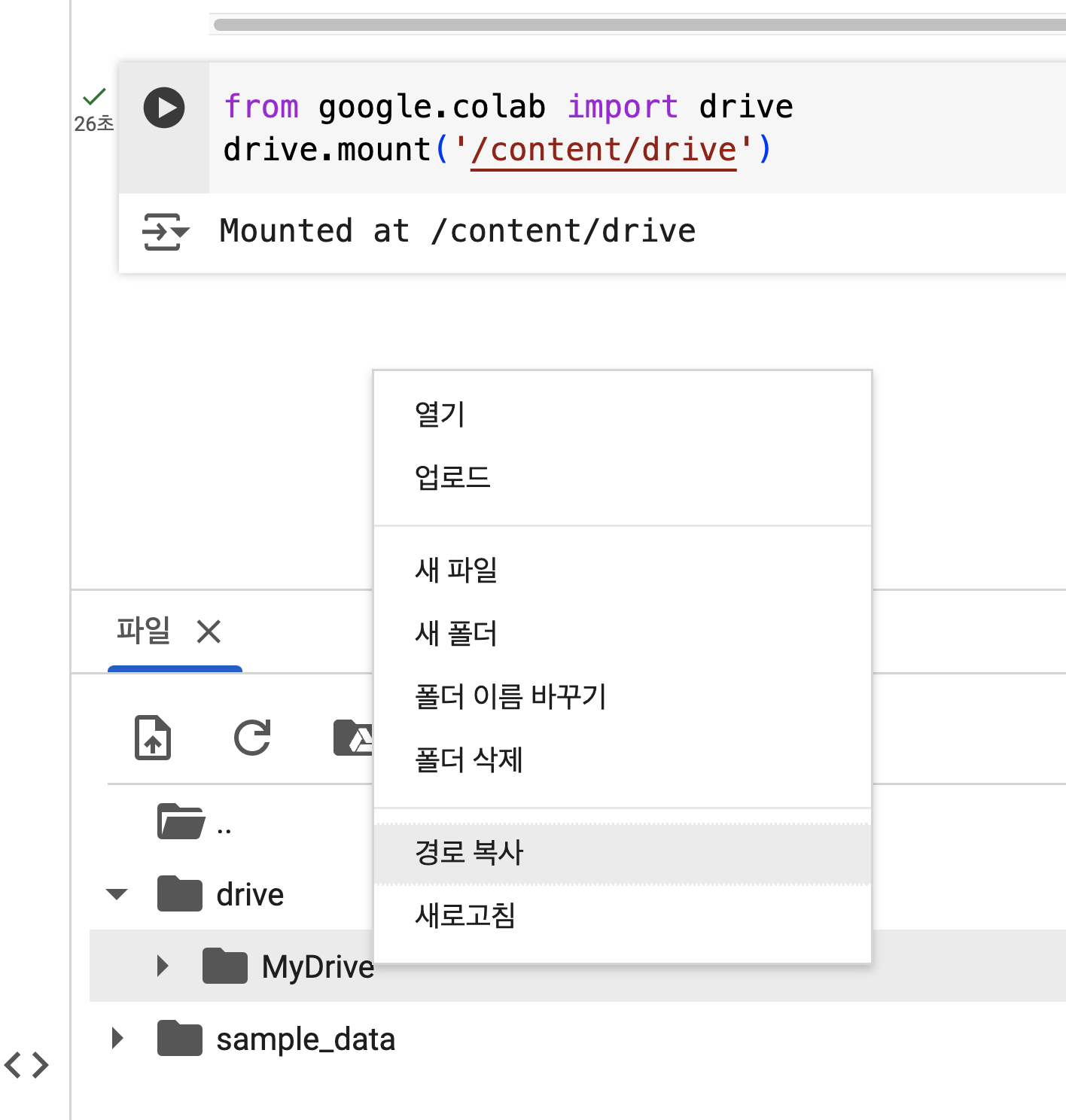
다음 코드를 사용하여 각 파일과 폴더의 경로를 설정하고, Excel 파일을 불러옵니다.
import os
import pandas as pd
# 설정 변수 (Google Drive 경로로 수정)
excel_file = '/content/drive/My Drive/pageNum.xlsx' # 페이지 번호가 기록된 Excel 파일
pdf_folder = '/content/drive/My Drive/원본PDF' # 원본 PDF 파일들이 저장된 폴더
output_folder = '/content/drive/My Drive/결과PDF' # 추출된 PDF 파일을 저장할 폴더
# 출력 폴더가 없으면 생성
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Excel 파일 읽기
df = pd.read_excel(excel_file)
# '파일명' 열이 있는지 확인
if '파일명' not in df.columns:
print("'파일명' 열이 Excel 파일에 존재하지 않습니다.")
exit()
'파일 업로드'를 사전에 실행했다면, 그 파일 마우스 우측 클릭을 통해 '경로 복사'를 할 수 있습니다.
설명:
1. excel_file: PDF 파일의 이름과 추출할 페이지 번호가 기록된 Excel 파일의 경로입니다.
2. pdf_folder: 추출할 원본 PDF 파일들이 저장된 폴더의 경로입니다.
3. output_folder: 추출된 PDF 파일을 저장할 폴더 경로입니다. 해당 폴더가 없을 경우 자동으로 생성됩니다.
4. pandas 라이브러리를 사용해 Excel 파일을 읽고, 데이터 프레임 형식으로 저장합니다.
***파일 확인
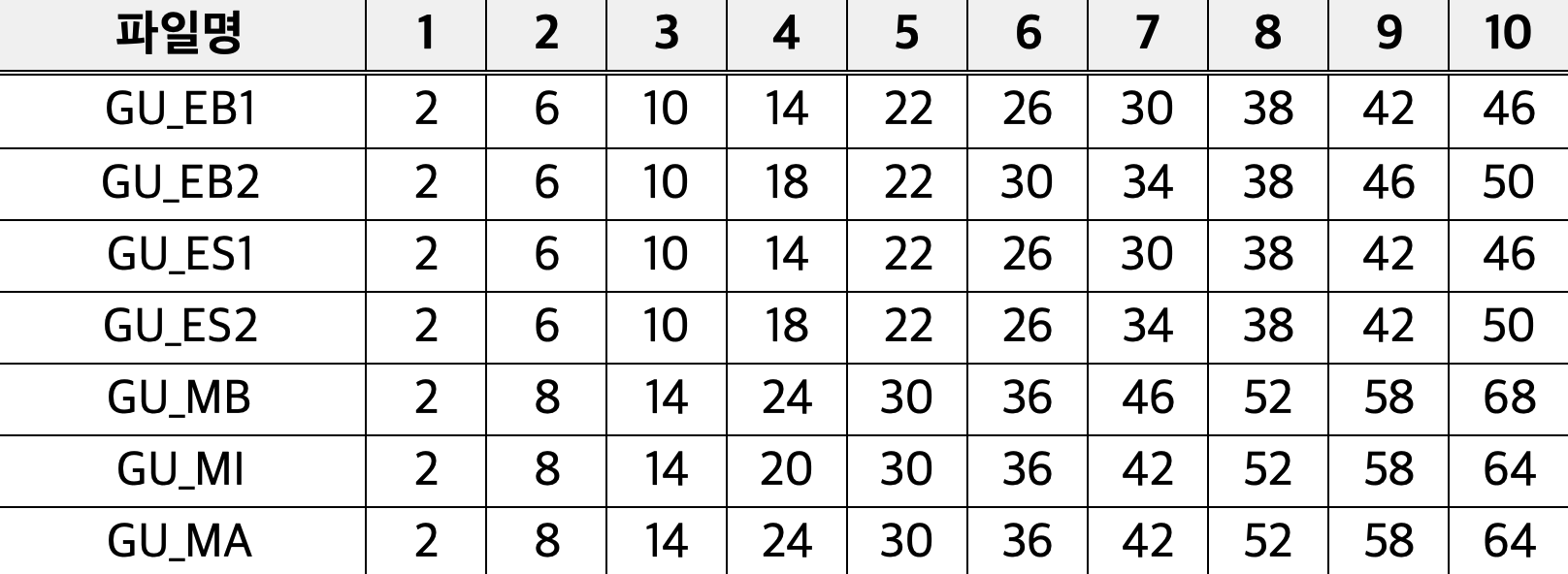
파일명은 실제 PDF랑 동일하게 설정하고, 위의 경우처럼 분할할 페이지를 10개 파트를 기준으로 작성하면 됩니다.
6. PDF 파일 처리 및 페이지 추출
이제 Excel 파일에서 PDF 파일명을 불러와, 각 파일에서 지정된 페이지를 추출하는 과정을 구현합니다. Excel 파일의 각 행에는 PDF 파일명과 페이지 번호가 들어 있습니다.
from PyPDF2 import PdfReader, PdfWriter
# 각 행에 대해 처리
for index, row in df.iterrows():
filename = row['파일명'] # PDF 파일명 추출
if pd.isna(filename):
continue
# 추출할 페이지 번호 리스트 생성
page_numbers = []
for col in df.columns:
if col == '파일명':
continue
page_num = row[col]
if pd.notna(page_num):
try:
page_numbers.append(int(page_num)) # 페이지 번호 추가
except ValueError:
print(f"유효하지 않은 페이지 번호: {page_num} (파일: {filename})")
if not page_numbers:
print(f"추출할 페이지가 없습니다: {filename}")
continue
# PDF 파일 경로 설정
pdf_path = os.path.join(pdf_folder, filename + '.pdf')
# PDF 파일이 존재하는지 확인
if not os.path.exists(pdf_path):
print(f"파일을 찾을 수 없습니다: {pdf_path}")
continue
# PDF 파일 읽기
reader = PdfReader(pdf_path)
writer = PdfWriter()
# PDF 페이지 추출
total_pages = len(reader.pages)
for page_num in page_numbers:
if 1 <= page_num <= total_pages:
writer.add_page(reader.pages[page_num - 1]) # 페이지 추가
else:
print(f"페이지 번호 {page_num}는 범위를 벗어났습니다 (파일: {filename}, 총 {total_pages} 페이지)")
설명:
1. PDF 파일명: Excel 파일에서 PDF 파일명을 가져와 파일 경로를 설정합니다.
2. 페이지 번호 리스트: Excel의 각 열에 있는 페이지 번호를 리스트로 변환하고, 유효한 페이지 번호만 처리합니다.
3. PDF 파일 읽기 및 페이지 추출: PyPDF2의 PdfReader로 PDF 파일을 읽고, 지정된 페이지들을 PdfWriter로 새로운 PDF 파일에 추가합니다.
7. 추출한 PDF 파일 저장
이제 추출한 페이지들을 하나의 PDF 파일로 저장합니다. 저장된 파일은 설정한 output_folder에 저장되며, 파일명은 {파일명}_extracted.pdf 형식으로 저장됩니다.
# 출력 파일 경로 설정
output_pdf_name = filename + '_extracted.pdf'
output_pdf_path = os.path.join(output_folder, output_pdf_name)
# PDF 저장
with open(output_pdf_path, 'wb') as f:
writer.write(f)
print(f"{output_pdf_name} 생성 완료.")
설명:
• 추출된 페이지를 새로운 PDF 파일로 저장하고, 그 경로는 output_folder에 지정됩니다.
• 파일 이름은 기존 파일명에 _extracted를 추가하여 저장합니다.
8. 전체 코드 실행 및 확인
위에서 설명한 모든 과정을 통해 PDF 파일에서 특정 페이지를 추출하는 자동화된 스크립트를 완성할 수 있습니다. 전체 코드를 실행하면 각 PDF 파일에서 추출한 페이지들이 결과 폴더에 저장됩니다.
import os
import pandas as pd
from PyPDF2 import PdfReader, PdfWriter
# 설정 변수 (Google Drive 경로로 수정)
excel_file = '/content/drive/My Drive/pageNum.xlsx'
pdf_folder = '/content/drive/My Drive/그래머 원본'
output_folder = '/content/drive/My Drive/G_out'
# 출력 폴더가 없으면 생성
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Excel 파일 읽기
df = pd.read_excel(excel_file)
# '파일명' 열이 있는지 확인
if '파일명' not in df.columns:
print("'파일명' 열이 Excel 파일에 존재하지 않습니다.")
exit()
# 각 행에 대해 처리
for index, row in df.iterrows():
filename = row['파일명']
if pd.isna(filename):
continue
# 추출할 페이지 번호 리스트 생성
page_numbers = []
for col in df.columns:
if col == '파일명':
continue
page_num = row[col]
if pd.notna(page_num):
try:
page_numbers.append(int(page_num))
except ValueError:
print(f"유효하지 않은 페이지 번호: {page_num} (파일: {filename})")
if not page_numbers:
print(f"추출할 페이지가 없습니다: {filename}")
continue
# 원본 PDF 파일 경로
pdf_path = os.path.join(pdf_folder, filename + '.pdf')
if not os.path.exists(pdf_path):
print(f"파일을 찾을 수 없습니다: {pdf_path}")
continue
# PDF 읽기
reader = PdfReader(pdf_path)
writer = PdfWriter()
# 페이지 추출
total_pages = len(reader.pages)
for page_num in page_numbers:
if 1 <= page_num <= total_pages:
writer.add_page(reader.pages[page_num - 1])
else:
print(f"페이지 번호 {page_num}는 범위를 벗어났습니다 (파일: {filename}, 총 {total_pages} 페이지)")
# 출력 파일 경로
output_pdf_name = filename + '_extracted.pdf'
output_pdf_path = os.path.join(output_folder, output_pdf_name)
# PDF 저장
with open(output_pdf_path, 'wb') as f:
writer.write(f)
print(f"{output_pdf_name} 생성 완료.")
마무리
이 튜토리얼을 통해 Google Colab 환경에서 PyPDF2와 pandas를 사용하여 PDF 파일에서 특정 페이지를 추출하는 과정을 자동화하는 방법을 배웠습니다. Google Drive와의 연동을 통해 손쉽게 클라우드에서 작업할 수 있으며, 반복적인 PDF 분할 작업을 효율적으로 처리할 수 있습니다.
이 방법을 통해 수백 개의 PDF 파일을 손쉽게 관리하고, 원하는 페이지를 추출하여 새로운 PDF 파일로 생성하는 작업을 자동화할 수 있습니다.
Colab을 활용하여 다양한 파일 작업을 진행해보세요!
*** 만약 파이썬으로 실행한다면, 아래 코드를 활용하면 됩니다.
import os
import pandas as pd
from PyPDF2 import PdfReader, PdfWriter
# 설정 변수
excel_file = 'pageNum.xlsx'
pdf_folder = '원본'
output_folder = '결과본'
# 출력 폴더가 없으면 생성
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Excel 파일 읽기
df = pd.read_excel(excel_file)
# '파일명' 열이 있는지 확인
if '파일명' not in df.columns:
print("'파일명' 열이 Excel 파일에 존재하지 않습니다.")
exit()
# 각 행에 대해 처리
for index, row in df.iterrows():
filename = row['파일명']
if pd.isna(filename):
continue
# 추출할 페이지 번호 리스트 생성
page_numbers = []
for col in df.columns:
if col == '파일명':
continue
page_num = row[col]
if pd.notna(page_num):
try:
page_numbers.append(int(page_num))
except ValueError:
print(f"유효하지 않은 페이지 번호: {page_num} (파일: {filename})")
if not page_numbers:
print(f"추출할 페이지가 없습니다: {filename}")
continue
# 원본 PDF 파일 경로
pdf_path = os.path.join(pdf_folder, filename + '.pdf')
if not os.path.exists(pdf_path):
print(f"파일을 찾을 수 없습니다: {pdf_path}")
continue
# PDF 읽기
reader = PdfReader(pdf_path)
writer = PdfWriter()
# 페이지 추출
total_pages = len(reader.pages)
for page_num in page_numbers:
if 1 <= page_num <= total_pages:
writer.add_page(reader.pages[page_num - 1])
else:
print(f"페이지 번호 {page_num}는 범위를 벗어났습니다 (파일: {filename}, 총 {total_pages} 페이지)")
# 출력 파일 경로
output_pdf_name = filename + '_extracted.pdf'
output_pdf_path = os.path.join(output_folder, output_pdf_name)
# PDF 저장
with open(output_pdf_path, 'wb') as f:
writer.write(f)
print(f"{output_pdf_name} 생성 완료.")
'업무_인공지능 활용 예시' 카테고리의 다른 글
| [Ollama] Llama3.2 Vision '영어 콘텐츠' 중심 모델 기능 검토 (11) | 2024.11.11 |
|---|---|
| [Excel/VBA] Excel VBA로 여러 시트 합치기: 코드 분석과 설명 (0) | 2024.10.08 |
| [GPT/크롤링] 주요 포털 사이트에서 크롤링이 필요한 정보를, GPT에게 시켜서 자동화하기 (3) | 2024.09.24 |
| [chatGPT/API] 영어 단어 또는 문장의 음원(mp3) 파일을 TTS 모델을 활용해서 제작하기 (2) | 2024.09.23 |



